Yuchao GuResearch Scientist at NVIDIAEmail: yuchaogu9710 [at] gmail.com
|
 |



Biography
- Efficient Generative Models: my work focuses on post-training for efficient visual generative models, including post-training token compression in (DC-Gen, Arxiv 2025), flow-map on-policy distillation for any-step video diffusion in (AnyFlow, Arxiv 2026), and long-context compression for causal video diffusion in (FAR, Arxiv 2025).
- Representation for Generation: my work first reveals the reconstruction-generation dilemma in vision tokenizers and answers how to build an effective visual latent space in (VQFR, ECCV 2022) and (RethinkVQ, CVPR 2024). Additionally, we study how to build effective action latent space for video world model in (Olaf-World, ICML 2026). I also collaborate in developing unified models for understanding and generation (Show-O, ICLR 2025), foundation model for video generation (Show-1, IJCV 2024).
- Controllable Visual Generation: my work explores a wide range of user control requirements, including multi-instance identity control (Mix-of-Show, NeurIPS 2023), multi-instance spatial control (ROICtrl, CVPR 2025), and video instance identity control (VideoSwap, CVPR 2024). I also collaborated on video editing (Tune-A-Video, ICCV 2023) and video motion control (MotionDirector, ECCV 2024).
Invited Talk
- 2026 Apr: Breaking Efficiency Barriers in Large-Scale Video Diffusion Models, Australian National University (hosted by Prof. Liang Zheng).
- 2025 May: Toward Long-Context Video World Modeling, Kuaishou Technology (hosted by Xintao Wang) and Twelvelabs (hosted by James Le).
News
- 2026 Apr: Olaf-World got accepted by ICML 2026.
- 2025 Feb: ROICtrl got accepted by CVPR 2025.
- 2025 Jan: Show-O got accepted by ICLR 2025.
- 2024 Sept: EvolveDirector got accepted by NeurIPS 2024.
- 2024 July: MotionDirector, DragAnything got accepted by ECCV 2024, with MotionDirector selected for Oral presentation.
- 2024 Feb: VideoSwap, RethinkVQ, DynVideo-E, MaskINT got accepted by CVPR 2024.
- 2023 Sept: Mix-of-Show, DatasetDM got accepted by NeurIPS 2023.
- 2023 Jun: Joined Meta GenAI as a Research Intern in Menlo Park, CA.
- 2023 July: Tune-A-Video got accepted by ICCV 2023.
- 2022 July: VQFR got accepted by ECCV 2022 as Oral.
- 2022 July: Joined Show Lab @ NUS to start my Ph.D. journey!
- 2021 Sep: Joined Tencent ARC Lab as a Research Intern.
Selected Publications
|
⚡ Efficient Generative Models
|
|
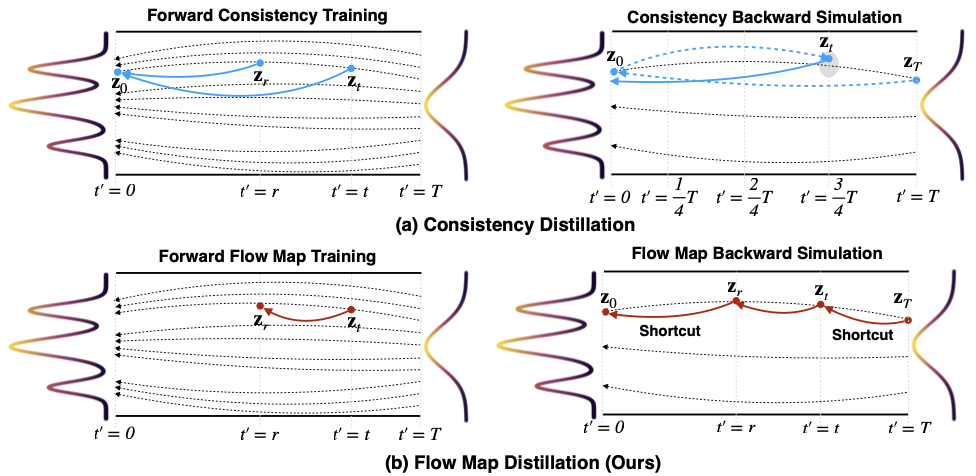
|
AnyFlow: Any-Step Video Diffusion Model with On-Policy Flow Map Distillation Yuchao Gu, Guian Fang, Yuxin Jiang, Weijia Mao, Song Han, Han Cai and Mike Zheng Shou. |

|
DC-Gen: Post-Training Diffusion Acceleration with Deeply Compressed Latent Space Wenkun He*, Yuchao Gu*, Junyu Chen*, Dongyun Zou, Yujun Lin, Zhekai Zhang, Haocheng Xi, Muyang Li, Ligeng Zhu, Jincheng Yu, Junsong Chen, Enze Xie, Song Han and Han Cai. |
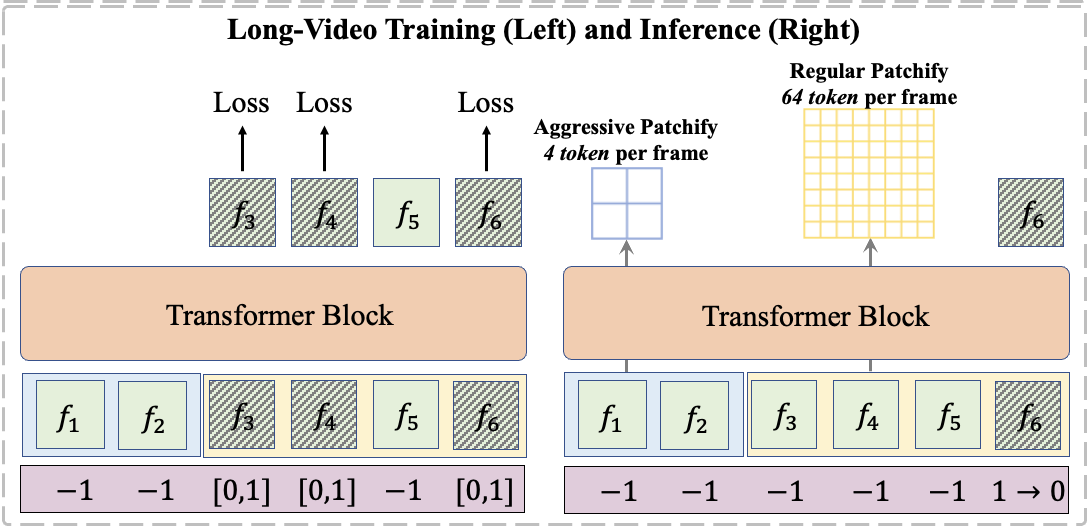
|
Long-Context Autoregressive Video Modeling with Next-Frame Prediction Yuchao Gu, Weijia Mao and Mike Zheng Shou. |
|
🧩 Representation for Generation
|
|
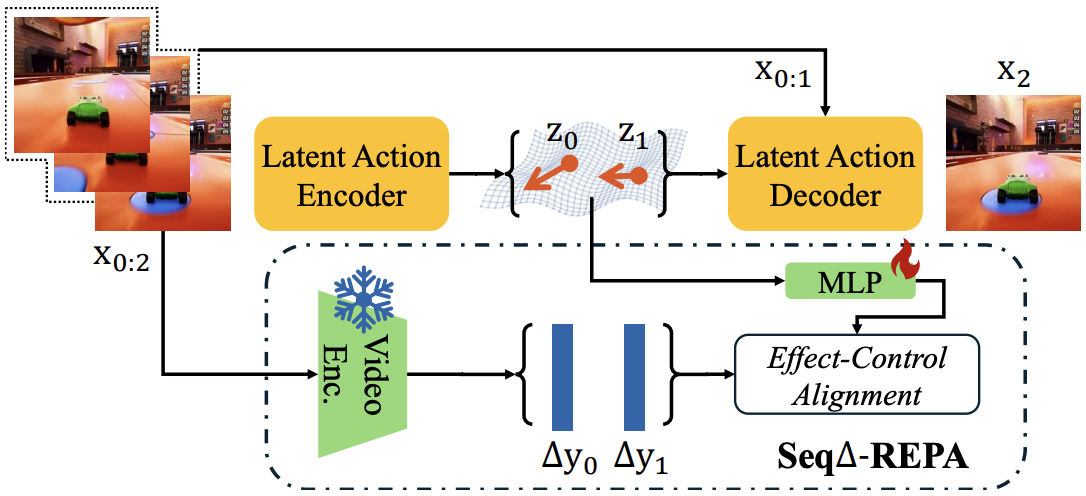
|
Olaf-World: Orienting Latent Actions for Video World Modeling Yuxin Jiang, Yuchao Gu, Ivor W. Tsang and Mike Zheng Shou.
International Conference on Machine Learning (ICML), 2026 |
|
Show-O: One Single Transformer to Unify Multimodal Understanding and Generation Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang and Mike Zheng Shou. |

|
Show-1: Marrying Pixel and Latent Diffusion Models for Text-to-Video Generation David Junhao Zhang, Jay Zhangjie Wu, Jia-Wei Liu, Rui Zhao, Lingmin Ran, Yuchao Gu, Difei Gao and Mike Zheng Shou. |
|
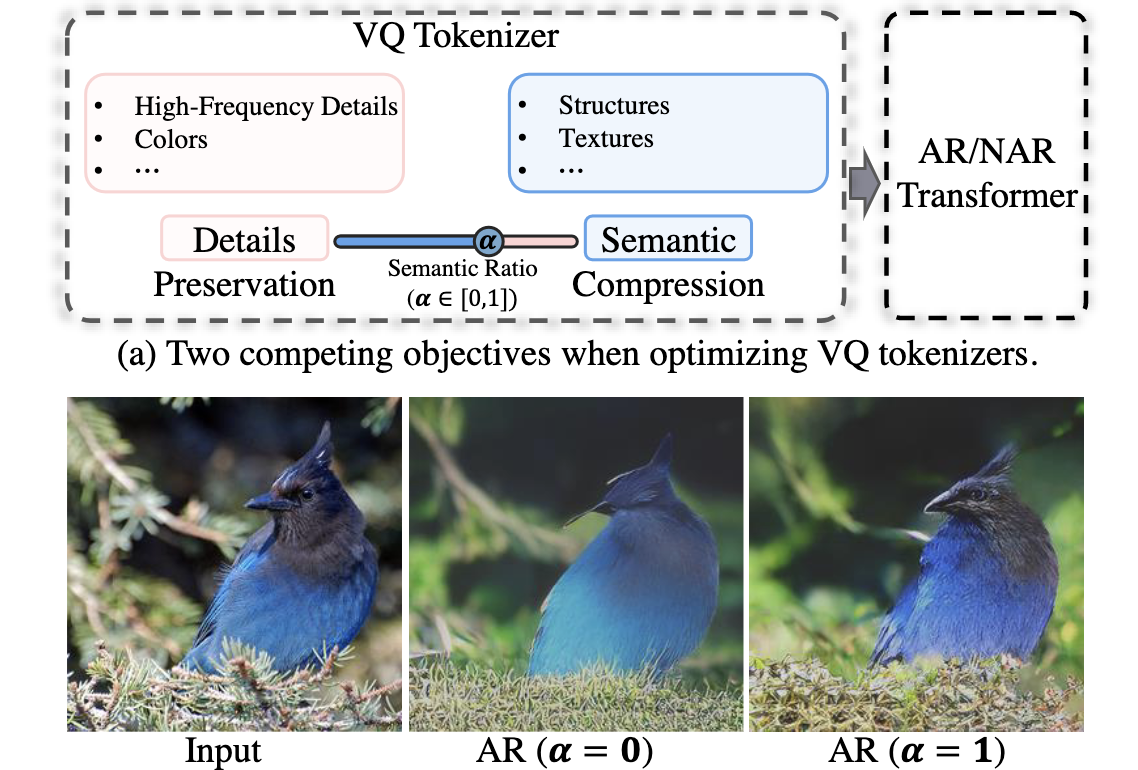
Rethinking the Objectives of Vector-Quantized Tokenizers for Image Synthesis Yuchao Gu, Xintao Wang, Yixiao Ge, Ying Shan, Xiaohu Qie and Mike Zheng Shou.
IEEE Computer Vision and Pattern Recognition Conference (CVPR), 2024 |
|
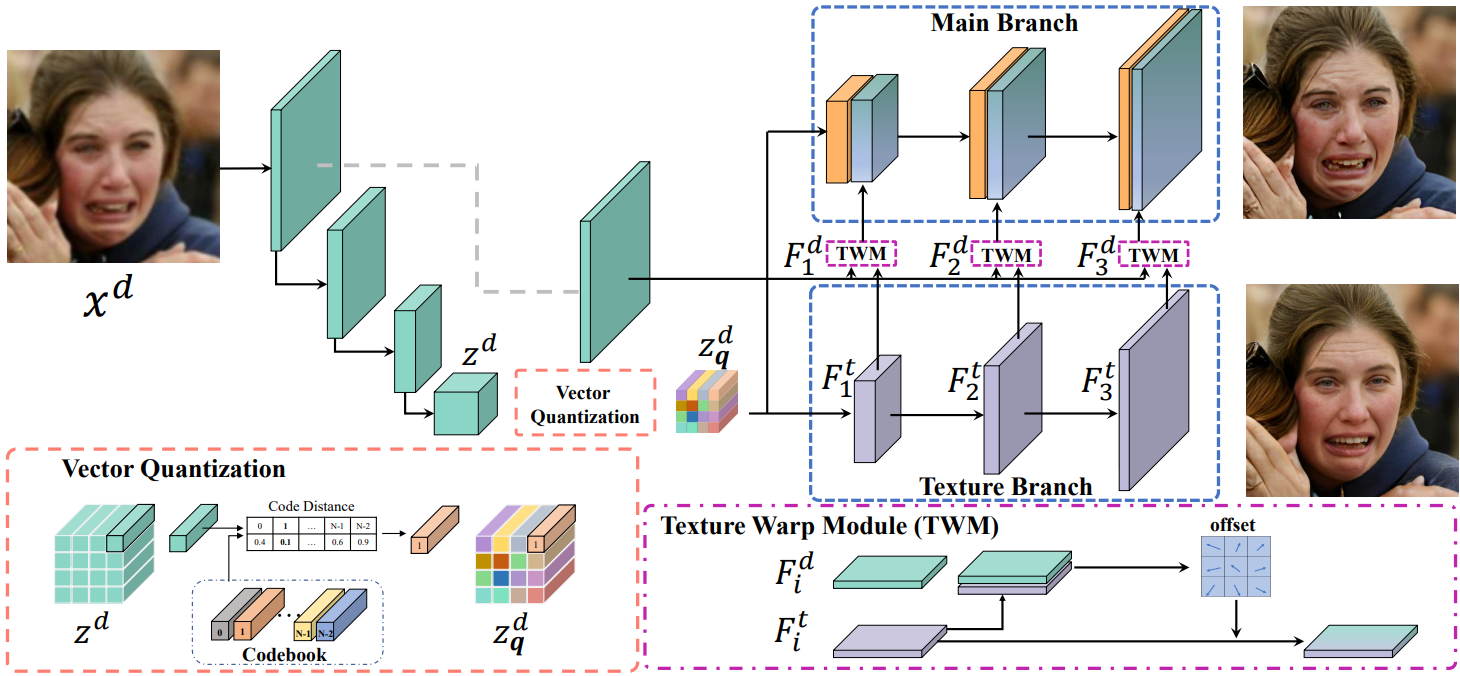
VQFR: Blind Face Restoration with Vector-Quantized Dictionary and Parallel Decoder
Yuchao Gu, Xintao Wang, Liangbin Xie, Chao Dong, Gen Li, Ying Shan and Ming-Ming Cheng.
European Conference on Computer Vision (ECCV, Oral), 2022 |
|
🎮 Controllable Visual Generation
|
|
|
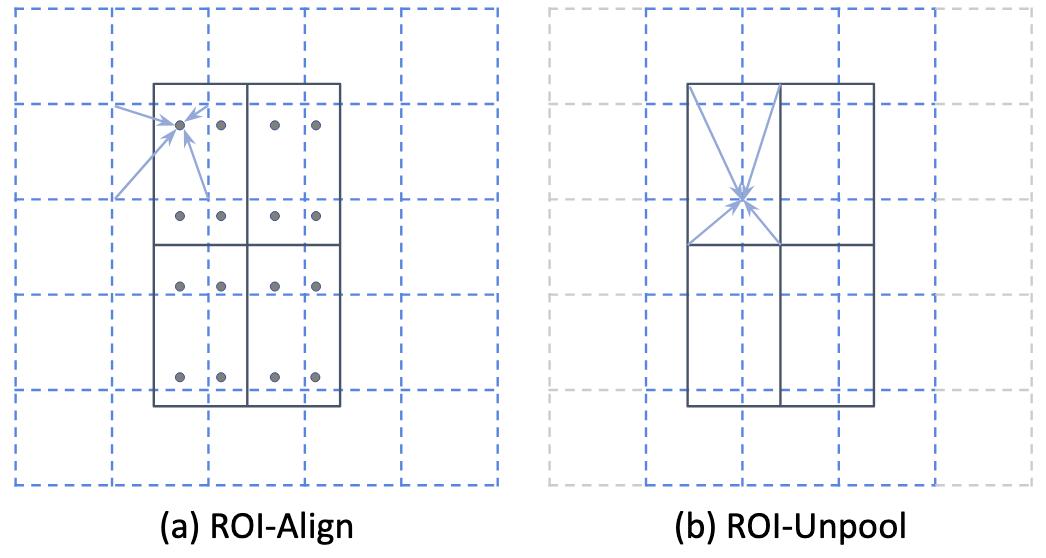
ROICtrl: Boosting Instance Control for Visual Generation Yuchao Gu, Yipin Zhou, Yunfan Ye, Yixin Nie, Licheng Yu, Pingchuan Ma, Kevin Qinghong Lin and Mike Zheng Shou.
IEEE Computer Vision and Pattern Recognition Conference (CVPR), 2025 |

|
MotionDirector: Motion Customization of Text-to-Video Diffusion Models Rui Zhao, Yuchao Gu, Jay Zhangjie Wu, David Junhao Zhang, Jiawei Liu, Weijia Wu, Jussi Keppo and Mike Zheng Shou.
European Conference on Computer Vision (ECCV, Oral), 2024 |

|
VideoSwap: Customized Video Subject Swapping with Interactive Semantic Point Correspondence Yuchao Gu, Yipin Zhou, Bichen Wu, Licheng Yu, Jiawei Liu, Rui Zhao, Jay Zhangjie Wu, David Junhao Zhang, Mike Zheng Shou and Kevin Tang.
IEEE Computer Vision and Pattern Recognition Conference (CVPR), 2024 |
|
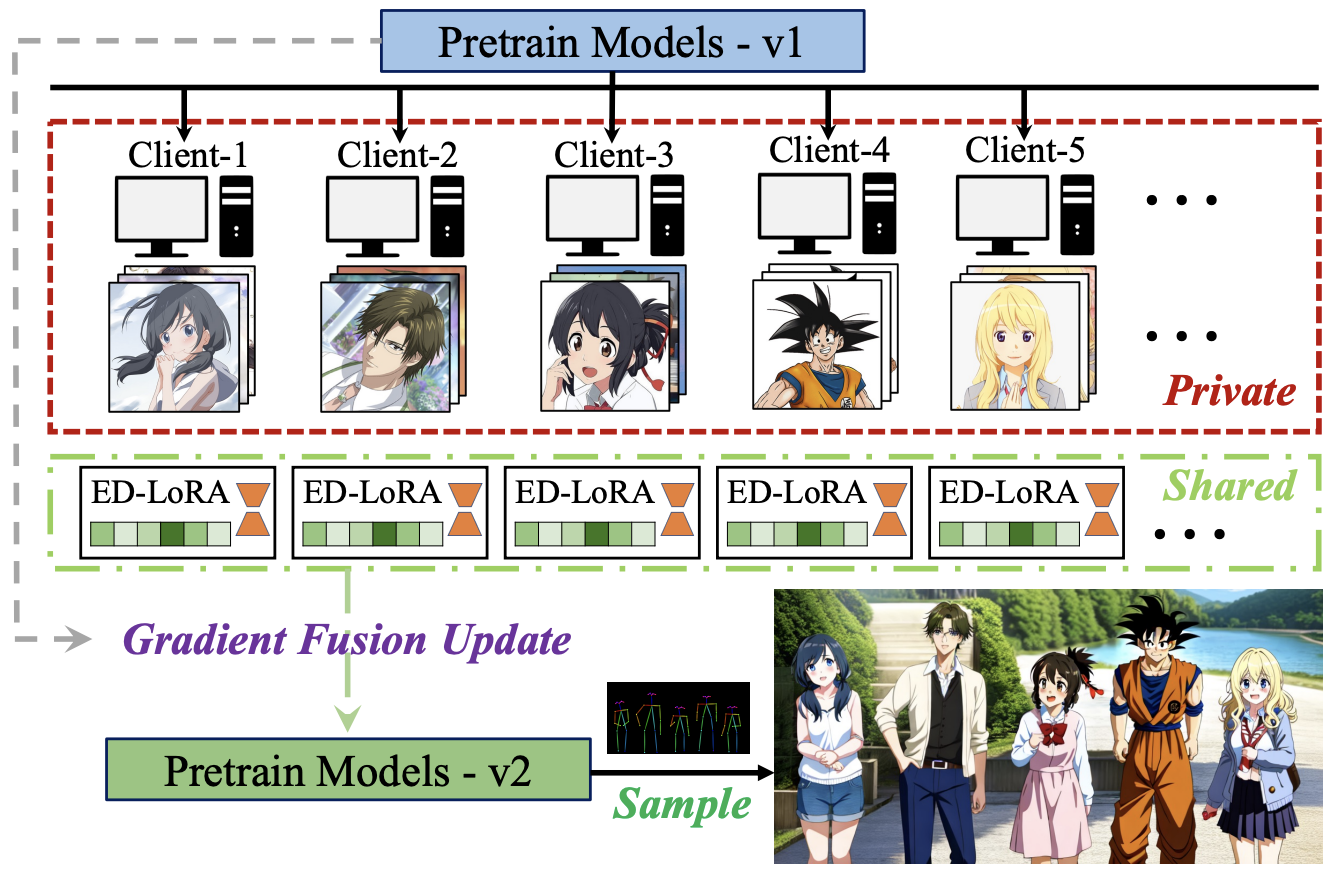
Mix-of-Show: Decentralized Low-Rank Adaptation for Multi-Concept Customization of Diffusion Models Yuchao Gu, Xintao Wang, Jay Zhangjie Wu, Yujun Shi, Yunpeng Chen, Zihan Fan, Wuyou Xiao, Rui Zhao, Shuning Chang, Weijia Wu, Yixiao Ge, Ying Shan and Mike Zheng Shou.
Neural Information Processing Systems (NeurIPS), 2023 |

|
Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Weixian Lei, Yuchao Gu, Wynne Hsu, Ying Shan, Xiaohu Qie and Mike Zheng Shou.
International Conference on Computer Vision (ICCV), 2023 |












Service
-
Conference Reviewer: CVPR, ICCV, ECCV, NeurIPS.
Acknowledgment
I have been fortunate to work with these wonderful people who generously provided me with collaboration and mentorship.|
@ ARC Lab, Tencent
|
@ GenAI, Meta
|
@ NVIDIA Research
|


